一、Java基础 1、说说JVM的内存结构,如何调整JVM内存? JVM内存结构:Java堆、方法区、程序计数器、JVM栈、本地方法栈 调整JVM内存: -Xms设置堆的最小空间大小。 -Xmx设置堆的最大空间大小。 -XX:NewSize设置新生代最小空间大小。 -XX:MaxNewSize设置新生代最大空间大小。 -XX:PermSize设置永久代最小空间大小。 -XX:MaxPermSize设置永久代最大空间大小。 -Xss设置每个线程的堆栈大小。
2、Java 中的final关键字有哪些用法? 1)用来修饰数据,包括成员变量和局部变量,该变量只能被赋值一次且它的值无法被改变。 对于成员变量来讲,我们必须在声明时或者构造方法中对它赋值; 2)用来修饰方法参数,表示在变量的生存期中它的值不能被改变; 3)修饰方法,表示该方法无法被重写; 4)修饰类,表示该类无法被继承。
3、说说下面程序输出什么结果? public class Test { public static void main(String[] args) { System.out.println(1.0f / 0); System.out.println(1/0); } } 第一个System.out.println输出Infinity, 第二个报异常: java.lang.ArithmeticException / by zero 解释:在Java虚拟机中,对于浮点在操作中遇到的非法操作,如被零除等不会抛出异常。
4、说说下面程序输出什么结果? public class Test { public static void main(String[] args) { float a = 1.1f; int b = (int) a; System.out.println(b); a += 1L; System.out.println(a); } } 解析:第一个System.out.println输出1 , 第二个输出2.1,原因是第一个是窄化类型转换,需要强转类型,会丢失精度,而第二个是宽化类型转换。
5、Error和Exception有什么区别? Error类一般是指与虚拟机相关的问题,如系统崩溃,虚拟机错误,内存空间不足,方法调用栈溢等。对于这类错误的导致的应用程序中断,仅靠程序本身无法恢复和和预防,遇到这样的错误,建议让程序终止。 Exception类表示程序可以处理的异常,可以捕获且可能恢复。遇到这类异常,应该尽可能处理异常,使程序恢复运行,而不应该随意终止异常。 Exception类又分为运行时异常(Runtime Exception)和受检查的异常(Checked Exception ),运行时异常;ArithmaticException,IllegalArgumentException,编译能通过,但是一运行就终止了,程序不会处理运行时异常,出现这类异常,程序会终止。而受检查的异常,要么用try catch捕获,要么用throws字句声明抛出,交给它的父类处理,否则编译不会通过。
6、列出一些你常见的运行时异常? NullPointerException - 空指针引用异常 ClassCastException - 类型强制转换异常。 IllegalArgumentException - 传递非法参数异常。 ArithmeticException - 算术运算异常 ArrayStoreException - 向数组中存放与声明类型不兼容对象异常 IndexOutOfBoundsException - 下标越界异常 NegativeArraySizeException - 创建一个大小为负数的数组错误异常 NumberFormatException - 数字格式异常 SecurityException - 安全异常 UnsupportedOperationException - 不支持的操作异常
7、简述synchronized 和java.util.concurrent.locks.Lock的异同? 主要相同点:Lock能完成synchronized所实现的所有功能
8、说说HashMap的存储原理。 HashMap 在底层将 key-value 当成一个整体进行处理,这个整体就是一个 Entry 对象。HashMap 底层采用一个 Entry[] 数组来保存所有的 key-value 对,当需要存储一个 Entry 对象时,会根据hash算法来决定其在数组中的存储位置,在根据equals方法决定其在该数组位置上的链表中的存储位置;当需要取出一个Entry时, 也会根据hash算法找到其在数组中的存储位置,再根据equals方法从该位置上的链表中取出该Entry。
二、网络基础 1、说说TCP三次握手的过程原理。
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接. 2、说说HTTP和HTTPS的区别。 1)https协议需要到ca申请证书,一般免费证书较少,因而需要一定费用。 2)http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。 3)http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。 4)http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
3、说说TCP和UDP的区别。 1)TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接; 2)TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付; 3)TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的 UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等); 4)每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信; 5)TCP首部开销20字节;UDP的首部开销小,只有8个字节; 6)TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道。
三、Linux基础 1、写出可以查看文档内容的命令。 cat 由第一行开始显示内容,并将所有内容输出 tac 从最后一行倒序显示内容,并将所有内容输出 more 根据窗口大小,一页一页的现实文件内容 less 和more类似,但其优点可以往前翻页,而且进行可以搜索字符 head 只显示头几行 tail 只显示最后几行 nl 类似于cat -n,显示时输出行号 tailf 类似于tail -f vim / vi 文本编辑
2、删除/home/test/dir文件夹的命令。 rm -rf /home/test/dir
3、如何查看当前Linux 系统的状态,如CPU 使用,内存使用,负载情况等。 使用top命令分析CPU使用,内存使用,负载等情况
四、前端基础 1、JavaScript获取某元素有哪些方式? getElementById、getElementsByTagName、getElementsByClassName
2、写出jQuery通过Ajax发送POST请求的js代码。 1)jQuery.post(url,data,success(data, textStatus, jqXHR),dataType) 2)$.ajax({ type: 'POST', url: url, data: data, success: success, dataType: dataType });
3、说说Javascript“==”和“===”之间的区别? ==”仅检查值相等,而“===”是一个更严格的等式判定,如果两个变量的值或类型不同,则返回false。
4、说说你熟悉JS框架有哪些? AngularJs、Vue、React、Node.js、Zepto.js、requirejs、backbone.js
五、数据库基础 1、现有rf_app_install_log表,pad_code为设备编码,log_type=1表示安装,log_type=2表示卸载,数据如下:
请统计设备的安装量、卸载量,展示结果按安装量降序。 select pad_code, sum(install_cnt) as 'install_cnt', sum(uninstall_cnt) as 'uninstall_cnt' from (select pad_code, if(log_type = 1, 1, 0) as 'install_cnt', if(log_type = 2, 1, 0) as 'uninstall_cnt' from rf_app_install_log) t group by pad_code order by install_cnt desc ;
2、索引是什么?有什么作用以及优缺点? 索引是一种特殊的文件(InnoDB数据表上的索引是表空间的一个组成部分),它们包含着对数据表里所有记录的引用指针。 一、为什么要创建索引呢(优点)? 创建索引可以大大提高系统的性能。 第一, 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。 第二, 可以大大加快数据的检索速度,这也是创建索引的最主要的原因。 第三, 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。 第四, 在使用分组和排序子句进行数据检索时,同样可以显著减少查询中分组和排序的时间。 第五, 通过使用索引,可以在查询的过程中,使用优化隐藏器,提高系统的性能。 二、建立方向索引的不利因素(缺点) 也许会有人要问:增加索引有如此多的优点,为什么不对表中的每一个列创建一个索引呢?这种想法固然有其合理性,然而也有其片面性。虽然,索引有许多优点,但是,为表中的每一个列都增加索引,是非常不明智的。这是因为,增加索引也有许多不利的一个方面。 第一, 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。 第二, 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。 第三, 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
3、数据库优化的方式。 sql层面:sql语句优化、索引优化。 数据库层面:分库分表分区、数据库集群、数据库+缓存。
4、MySQL数据库的存储引擎有哪些? 1) MyISAM:这种引擎是mysql最早提供的。这种引擎又可以分为静态MyISAM、动态MyISAM 和压缩MyISAM三种: 静态MyISAM:如果数据表中的各数据列的长度都是预先固定好的,服务器将自动选择这种表类型。因为数据表中每一条记录所占用的空间都是一样的,所以这种表存取和更新的效率非常高。当数据受损时,恢复工作也比较容易做。 动态MyISAM:如果数据表中出现varchar、xxxtext或xxxBLOB字段时,服务器将自动选择这种表类型。相对于静态MyISAM,这种表存储空间比较小,但由于每条记录的长度不一,所以多次修改数据后,数据表中的数据就可能离散的存储在内存中,进而导致执行效率下降。同时,内存中也可能会出现很多碎片。因此,这种类型的表要经常用optimize table 命令或优化工具来进行碎片整理。 压缩MyISAM:以上说到的两种类型的表都可以用myisamchk工具压缩。这种类型的表进一步减小了占用的存储,但是这种表压缩之后不能再被修改。另外,因为是压缩数据,所以这种表在读取的时候要先时行解压缩。 但是,不管是何种MyISAM表,目前它都不支持事务,行级锁和外键约束的功能。 2 )MyISAM Merge引擎:这种类型是MyISAM类型的一种变种。合并表是将几个相同的MyISAM表合并为一个虚表。常应用于日志和数据仓库。 3) InnoDB:InnoDB表类型可以看作是对MyISAM的进一步更新产品,它提供了事务、行级锁机制和外键约束的功能。 4) memory(heap):这种类型的数据表只存在于内存中。它使用散列索引,所以数据的存取速度非常快。因为是存在于内存中,所以这种类型常应用于临时表中。 5)archive:这种类型只支持select 和 insert语句,而且不支持索引。常应用于日志记录和聚合分析方面。
5、说说你熟悉的数据库中间件。 MyCat、Cobar、DRDS/TDDL、Altas、Vitess、Heisenberg、CDS、 DDB、 OneProxy
六、其他 1、Spring AOP的工作原理。 动态代理
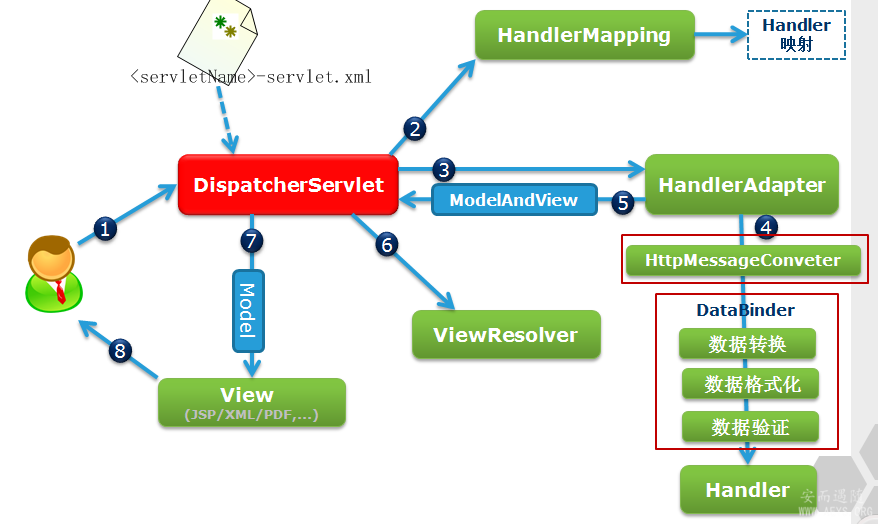
2、Spring MVC的工作流程。
1、用户发送请求至前端控制器DispatcherServlet 3、在MyBatis中,#{}和${}的区别是什么? 1)#将传入的数据都当成一个字符串,会对自动传入的数据加一个双引号。如:order by #user_id#,如果传入的值是111,那么解析成sql时的值为order by "111", 如果传入的值是id,则解析成的sql为order by "id". 2)$将传入的数据直接显示生成在sql中。如:order by $user_id$,如果传入的值是111,那么解析成sql时的值为order by user_id, 如果传入的值是id,则解析成的sql为order by id. 3)#方式能够很大程度防止sql注入。 4)$方式无法防止Sql注入。 5)$方式一般用于传入数据库对象,例如传入表名. 6)一般能用#的就别用$.
4、写出你熟悉的设计模式。 创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。 结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。 行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
5、SOA和微服务的区别是什么? 1)微服务相比于SOA更加精细,微服务更多的以独立的进程的方式存在,互相之间并无影响; 2)微服务提供的接口方式更加通用化,例如HTTP RESTful方式,各种终端都可以调用,无关语言、平台限制; 3)微服务更倾向于分布式去中心化的部署方式,在互联网业务场景下更适合;
6、写出你熟悉的Web应用服务器。 Tomcat、Jetty、WebLogic、Resin、Nginx、Apache、IIS
7、假设服务器经常宕机,你从哪些方面去排查问题? 一般情况下,有可能是资源跑满(被攻击),服务器无法承受就宕机了,还有就是系统故障,最后就是硬件问题了,逐步排查,看看日志,总能发现问题的。 8、redis与memcached有什么区别? 1)redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储 2)内存使用使用效率对比 使用简单的key-value存储的话,memcached的内存利用率会更高一点,如果redis采用hash结构来做key-value存储,由于其组合式的压缩,内存的利用率更高。 3)性能对比:由于redis只使用单核,而memcached使用多核,所以平均在每一个核上redis在存储小数据时比memcached性能更高,而在100Ks=以上的时候memcached性能要高于redis 4)内存管理机制的不同 在redis中,并不是所有的数据都一一直存储在内存中的,这是和memcached相比最大的一个区别 Redis只会缓存所有的key端的信息,如果redis发现内存的使用量超过某一个值,将触发swap的操作,redis根据相应的表达式计算出那些key对应value需要swap到磁盘,然后再将这些这些key对应的value持久化到磁盘中,同时再内存清除。同时由于redis将内存中的数据swap到磁盘的时候,提供服务的主线程和进行swap操作的子进程会共享这部分内存,所以如果更新需要swap的数据,redis将阻塞这个操作,直到子线程完成swap操作后才可以进行修改 5)数据持久化的支持 虽然redis是基于内存的存储系统,但是他本身是支持内存数据的持久化,而且主要提供两种主要的持久化策略,RDB快照和AOF日志,而memcached是不支持数据持久化的操作的。 RDB持久化通过保存了数据库的健值对来记录数据库状态的不同,AOF持久化是通过保存reds服务器所执行的命令来保存记录数据库的状态的, RDB持久化保存数据库状态的方法是将msg,fruits,numbers三个健的健值对保存到RDB文件中,而AOF持久化保存数据库的状态则是将服务器执行的SET,SADD,RPUSH三个命令保存到AOF文件中的
|
 解决 Wn10无法连接 蓝牙耳
解决 Wn10无法连接 蓝牙耳 Python之Selenium知识总结
Python之Selenium知识总结 2万字带你了解Selenium全攻
2万字带你了解Selenium全攻 解决网站网页不能复制,不
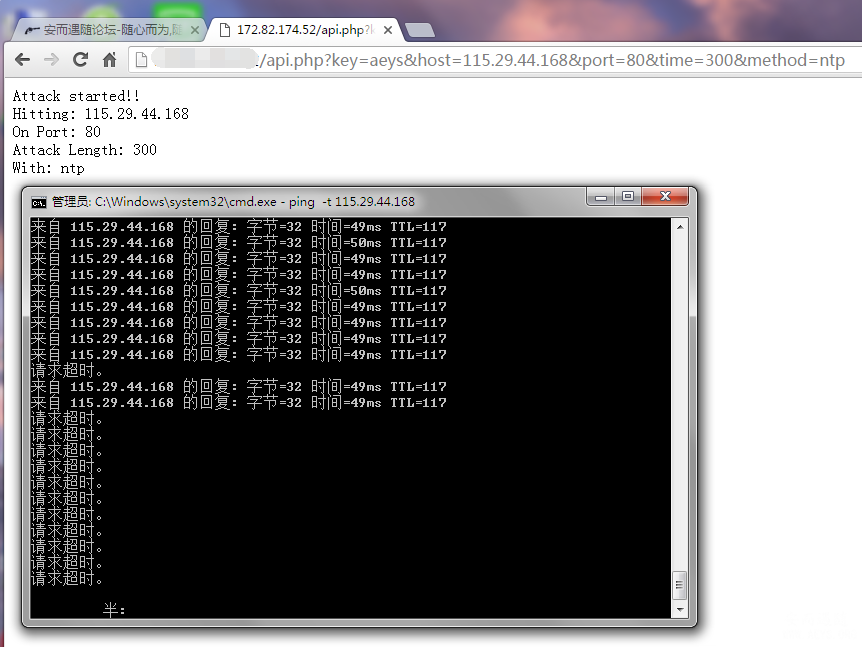
解决网站网页不能复制,不 我对ddos攻击的见解以及ufo
我对ddos攻击的见解以及ufo